
Machine learning (ML) – Machine learning remains a branch of artificial intelligence (AI) besides computer science. It mainly emphasizes utilizing data and algorithms to copy how humans learn, progressively improving accuracy. It remains a kind of artificial intelligence that lets software requests predict outcomes more accurately without being explicitly automatic. Machine erudition algorithms use historical data as input to predict new output values.
Recommendation engines are an ordinary use case for machine learning. Other common uses include fraud detection, spam filtering, malware threat detection, business process automation (BPA), and predictive maintenance.
Table of Contents
Why is Machine Learning Important?

In today’s Technical world, machine learning is growing in importance because of its enormous volumes, wide range of data, and the availability of high-speed internet. These factors are responsible for the rapid and automatic development of models. These models rapidly and accurately study extensive and complex data sets.
Machine learning is crucial because it gives companies insight into trends in customer behavior and business models. It also supports the development of new products. It has become an essential competitive advantage for many businesses.
Different Types
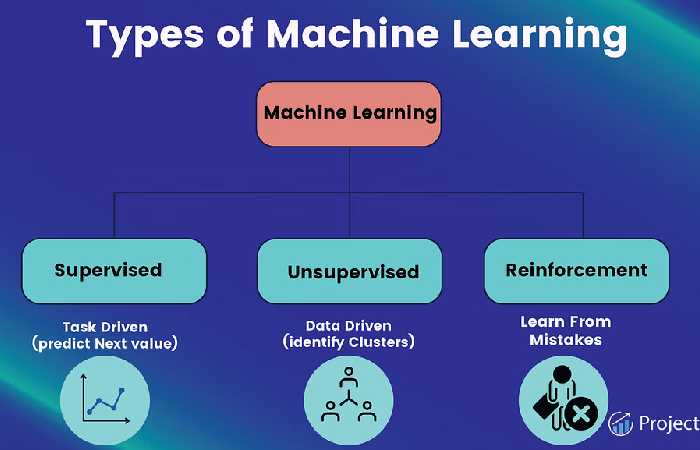
Classic is often classified based on how an algorithm learns to be more precise in its predictions.
There Are Four Basic Approaches:
Supervised learning, unsupervised learning, semi-supervised learning, and reinforced learning. The type of data algorithm scientists use depends on the data they want to predict.
Supervised Learning:
In this category of machine learning data, scientists provide the algorithms with labeled training data. It also defines the variables that the algorithm must evaluate for the correlations. The input and output of the procedure remain specified.
Unsupervised Learning:
This uses algorithms that are trained on unlabeled data. The algorithm searches for records for a meaningful connection. The data with which the algorithms are introduced and the predictions or recommendations they generate are predetermined.
Semi-Supervised Learning:
This approach involves a combination of the two previous types. Data scientists can power an algorithm known primarily as training data, but the model can examine the data independently and grow its understanding of the data set.
Reinforcement Learning:
Data scientists often use reinforcement learning to train a machine to perform a multistep process with clearly defined rules. Data scientists package an algorithm to accomplish a duty. It also sends you positive or negative signals to determine how a job is performed. However, most of the time, the algorithm itself decides what steps to take.
How Does Supervised Machine Learning Work?
The data scientist has the algorithm with labeled inputs and desired outputs in supervised machine learning. Supervised learning algorithms are well suited to the following tasks:
Binary classification: divide the data into two categories.
Multiclass variety: choose from more than two types of answers.
Regression modeling: prediction of continuous values.
Combine predictions from multiple machine learning models to produce an accurate forecast.
How Does Unsupervised Machine Learning Work?
Unsupervised machine education algorithms do not require data labeling. You examine unlabeled data for models that can group data opinions into subsets. Most types of profound learning, including neural networks, are unsupervised algorithms. Unsupervised learning algorithms are well suited to the following tasks:
Grouping: Divide the dataset into groups based on similarity.
Anomaly Detection – Identifying unusual data points in a dataset.
Exploring associations: Identifying items in a dataset that often appear together.
Dimension reduction: Reduce the number of variables in a data set.
Advantages And Disadvantages Of Machine Learning
Machine learning consumes routine cases ranging from predicting client behavior to training the operating system for self-driving cars.
Advantages
In terms of benefits, collecting customer data can help businesses better understand their customers. Algorithms can also study associations by correlating them with behavior over time. It also allows teams to tailor invention development and marketing initiatives to meet customer demand.
However, some companies use machine learning as the primary driver of their business models. For example, Uber uses algorithms to match drivers and passengers. Google uses it to show travel ads in search queries.
Disadvantages
Machine learning also has some drawbacks. First, it can get expensive. Projects are often driven by data scientists who earn high salaries. These projects also require software infrastructure, which can remain costly.
There also remains the problem of it. Algorithms trained on datasets that exclude specific populations or contain errors can lead to inaccurate models of the world that fail at best and are, at worst, discriminatory. However, If a company builds its core business processes on distorted models, it can suffer reputational and regulatory damage.
Also Read: What Is Blockchain Technology? – Advantages, Elements, And More